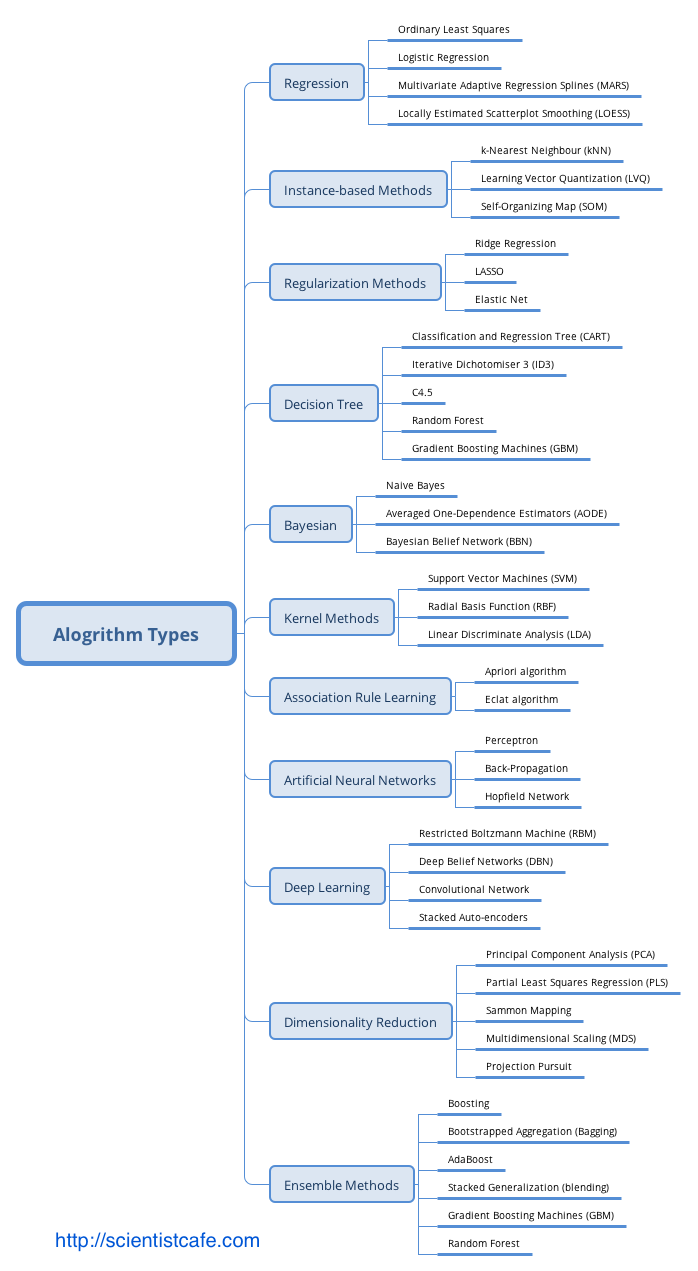
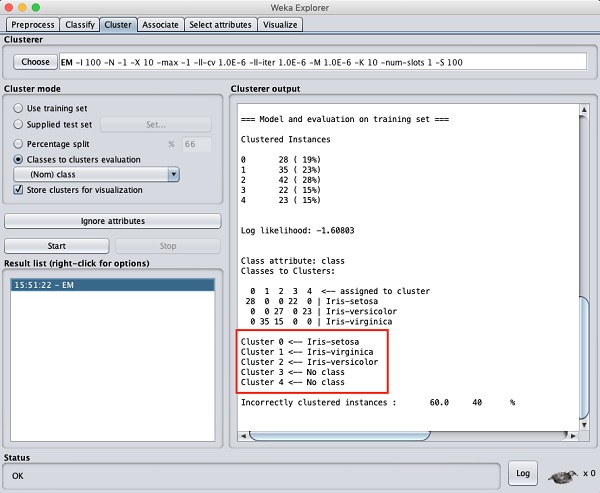
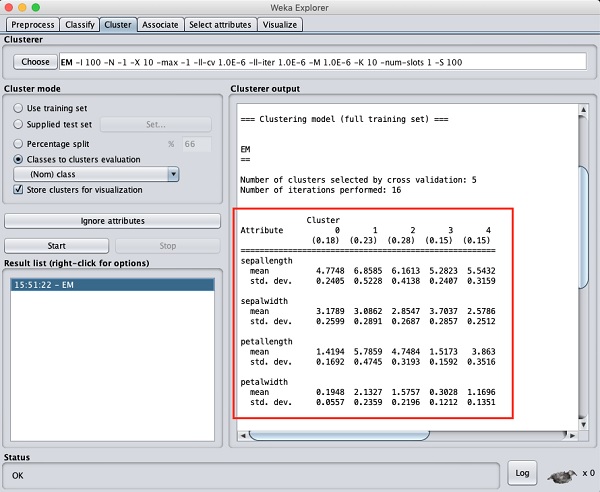
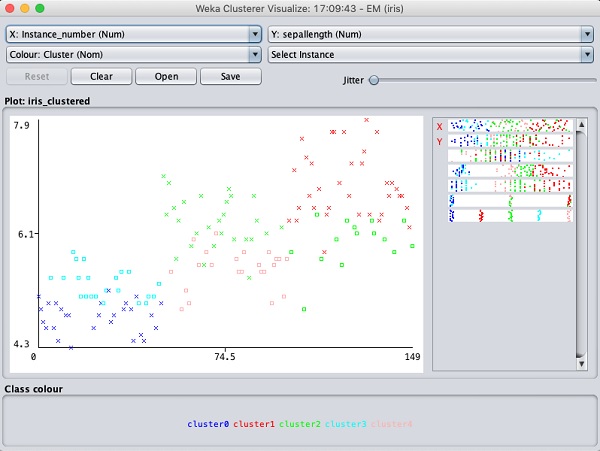
TÜRKİYE CUMHURİYET MERKEZ BANKASI VERİ YÖNETİMİ STRATEJİLERİ RAPORU HAZIRLAYAN MURAT ÇAKIR Yönetici Özeti: Merkez Bankası Veri Yönetimi Stratejileri Raporu Sayın Başkanım, Bu yönetici özeti, Türkiye Cumhuriyet Merkez Bankası için hazırlanan Veri Yönetimi Stratejileri Raporu'ndaki önemli noktaları vurgulamaktadır. Söz konusu raporun amacı, Merkez Bankasının fiyat ve finansal istikrarı koruma misyonunu güçlendirmek amacıyla verilerin etkin bir şekilde yönetilmesi, analizi ve kullanımı için gerekli çerçeveyi oluşturmaktır. Halihazırdaki durumun değerlendirildiği rapor ayrıca sunulacaktır. Arka Plan ve Amaç: Verinin giderek artan önemi ve içinde bulunduğumuz dijital dönüşüm çağında, verilerin stratejik bir varlık olarak kullanılmasının önemi ve gerekliliği açıktır. Veri Yönetimi Stratejileri Raporu, bankanın bilgiye dayalı ve veri odaklı karar alma süreçlerini desteklemeyi ve veri analitiği alanı ve bilişim teknolojilerindeki en son yeniliklerin kurum içinde hayat geçirilmesini teşvik etmeyi amaçlamaktadır. Ana Başlıklar: Rapor, aşağıdaki ana başlıklara odaklanmaktadır: 1. Veri Yönetişimi: Veri yönetimi politikaları geliştirme, veri sorumluluğu tanımlama ve Veri Yönetişim Kurulu oluşturulmasıyla veri yönetişiminin sağlanması, 2. Veri Toplama ve Entegrasyon: Tüm veri kaynaklarının tanımlanması, veri toplama prosedürlerinin belirlenmesi ve yüksek veri kalitesi güvencesinin sağlanması, 3. Veri Analitiği ve İçgörüler: Gelişmiş öngörü modelleri inşası için ileri düzey analitik tekniklerin geliştirilmesi ve verinin etkili bir şekilde görselleştirilmesi, 4. Veri Güvenliği ve Gizlilik: Güçlü ve sağlam siber güvenlik önlemlerinin alınması, veri gizliliği uyumunun sağlanması ve erişim kontrollerinin uygulanması, 5. Veri Altyapısı: Modern donanım ve uzaktan erişim (sanal sunucu, iş istasyonu ve kurum dışından erişim için kümeleme ve GPU bilişim) çözümleri kullanarak veri altyapısınının güçlendirilmesi ve 6. Kapasite Geliştirme: Eğitim ve iş birliği fırsatları aracılığıyla çalışanların veri analitiği ve yönetimi konusundaki yetkinliklerinin geliştirilmesi ve/veya artırılması hedeflenmektedir. 7. Uygulama Yol Haritası: Kısa, orta ve uzun vadeli hedefler belirlenmiş olup, bu hedeflerin nasıl gerçekleştirileceği adım adım açıklanmaktadır. Sonuç: Veri Yönetimi Stratejileri Raporu, Türkiye Cumhuriyet Merkez Bankası’nın misyonunu daha etkili bir şekilde yerine getirebilmesi için verinin kamuoyunun bilgilendirilmesi ve karar alım süreçlerinde stratejik bir araç olarak kullanılmasına yönelik tasarım, uygulama ve yönetim çalışma ve çabalarının çerçevesini sunmaktadır. Kurumun veri stratejilerinin başarılı bir şekilde uygulanması ile veri analitiği alanı ve bilişim teknolojilerindeki en son yenilikler hayata geçirilecek, böylece karar alma süreçlerinin güçlendirilmesi ile ekonomik ve finansal istikrarı sağlama misyonu en optimal şekilde yerine getirilebilecektir. Saygılarımla bilgilerinize sunarım, Murat Çakır Merkez Bankası Veri Yönetimi Stratejileri Raporu Yönetici Özeti Veri Yönetimi Stratejileri Raporu, Türkiye Cumhuriyet Merkez Bankası bünyesinde sağlam bir veri stratejisi uygulamanın amaç ve gerekleri ile bu stratejinin çerçeve taslağını sunmaktadır. Merkez bankalarında veriyi kullanma ile bilgiye dayalı ve veri odaklı karar almanın önemi, diğer tüm iktisadi karar alıcılarda da olması gerektiği gibi, misyonlarının etkili bir şekilde yerine getirebilmesi için gitgide yükselen bir hızla artmaktadır. Bu bağlamda, Merkez Bankası Veri Yönetimi Stratejileri Raporu, veri yönetişimi, veri yönetimi ve veri kullanımı için kapsamlı bir çerçeve oluşturmayı amaçlamaktadır. Halihazırdaki durumun değerlendirildiği rapor ayrıca sunulacaktır. İçindekiler Giriş 1.1 Arka Plan 1.2 Veri Stratejisinin Amacı Veri Yönetişimi 2.1 Yönetişim Yapısı 2.2 Veri Yönetişim Politikaları 2.3 Veri Sorumluluğu Veri Toplama ve Entegrasyon 3.1 Veri Kaynakları 3.2 Veri Toplama Prosedürleri 3.3 Veri Entegrasyonu ve Kalite Güvencesi Veri Analitiği ve İçgörüler 4.1 Gelişmiş Analiz Altyapısı 4.2 Öngörü Modelleme 4.3 Veri Görselleştirme Veri Güvenliği ve Gizlilik 5.1 Siber Güvenlik Önlemleri 5.2 Veri Gizliliği Uyumu 5.3 Erişim Kontrolü Veri Altyapısı 6.1 Donanım ve Yazılım 6.2 Uzaktan Erişim 6.3 Veri Depolama Kapasite Geliştirme 7.1 Eğitim ve Yetenek Geliştirme 7.2 İşe Alma Stratejileri 7.3 Eğitim Kurumlarıyla İş Birliği Veri Stratejisi Uygulama Yol Haritası 8.1 Kısa Vadeli Hedefler 8.2 Orta Vadeli Hedefler 8.3 Uzun Vadeli Hedefler İzleme ve Değerlendirme 9.1 Anahtar Performans Göstergeleri (KPI'lar) 9.2 Düzenli Denetimler ve İncelemeler 10. Sonuç 11. Uygulama Yol Haritası 12. Sözlük 14. Ekler 1. Giriş 1.1 Arka Plan Türkiye Cumhuriyet Merkez Bankası, kanunuyla kendisine verilen görevleri etkili bir şekilde yerine getirebilmek için, veriyi stratejik bir varlık olarak kullanma ve bilgiye dayalı ve veri odaklı karar almanın öneminin bilinciyle çok uzun yıllardır ilgili alanlarda gereken çalışmaları yerine getirmiş ve gerekli yatırımları yapmıştır. Bu yönüyle, ülkemizdeki en erken dijitalleşme çalışmalarının yürütülmesi, ulusal ve uluslararası eşgüdüm ve işbirliği çerçevesinde çeşitli çalışmalarında yer alınan kurullar ve ortak yürütülen projelerdeki faaliyetler, veri üretimi ve paylaşımı, ve benzeri bir çok konuda öncü olmuştur. Kurum içinde gerçekleştirilen çalışma ve projelerin önemli bir bölümü de ya dünya çapında ilk ya da benzer örneklerinin ötesinde olma özelliği taşımaktadır . TCMB’nin, aynı bilinçle yeni bir bakış açısı ve enerjiyle her konuda olduğu gibi veri süreçlerinde de çağın gereklerini yakalaması ve öncü rolü üstlenmesi gerekliliği açıktır. Bu bağlamda, Veri Yönetimi Stratejileri Raporu ile verinin etkili bir şekilde yönetilmesi, güvenliğinin sağlanması ve tam potansiyeliyle kullanılmasını sağlayan bir çerçeve oluşturulması amaçlanmıştır. 1.2 Veri Stratejisinin Amacı Veri Stratejisinin temel amacı: • Bilinçli karar alma için verinin kalitesini ve erişilebilirliğini artırmak, • Veri yönetişimi için sağlam bir yapı oluşturarak uyum ve veri bütünlüğünü sağlamak, • İleri düzeyde analitik yöntemlerin kullanımını hayata geçirerek para politikasını, finansal düzenlemeleri ve ekonomik araştırmaları desteklemek, • Veriyi siber güvenlik önlemleri ve gizlilik uyumlarıyla korumak, • Sürdürülebilir bir veri altyapısı oluşturmak ve • Çalışanların veriyi etkili bir şekilde yönetme ve analiz etme yeteneklerini geliştirmek olarak özetlenebilir. 2. Veri Yönetişimi 2.1 Yönetişim Yapısı Bankanın veri ile ilintili politikalarını, prosedürlerini ve uyumunu denetlemek üzere özel bir Veri Yönetişim Kurulu oluşturulacaktır. Bu kurul, çeşitli birimlerden temsilciler içerecek ve veri politikalarının Merkez Bankasının stratejik hedefleriyle uyumunu sağlayacaktır. 2.2 Veri Yönetişim Politikaları Güçlü ve sağlam veri yönetişimi politikaları oluşturulacak ve uygulamaya konacak, böylece veri işleme, sınıflandırma, depolama ve paylaşma süreçleri yönetilecektir. Bu politikalar, veri saklama, arşivleme ve imha politikalarını da içermektedir. 2.3 Veri Sorumluluğu Her bir birim içinde veri sorumluları belirlenerek veri kalitesi, doğruluğu ve uyum için sorumluluk ve hesap verebilirlik sağlanacaktır. Veri sorumluları, Veri Yönetişim Kurulu ile yakın iş birliği ve eşgüdüm içinde çalışacaklardır. 3. Veri Toplama ve Entegrasyon 3.1 Veri Kaynakları Tüm veri kaynakları, iç ve dış ve yapılandırılmış ve yapılandırılmamış olmak üzere belirlenecek ve kataloglanacaktır. Veri kaynakları iyi belgelenmeli ve erişilebilir olmalıdır. 3.2 Veri Toplama Prosedürleri Veri toplama için standartlaştırılmış prosedürler belirlenecek ve böylece veri tutarlılığı, doğruluğu ve verilerin zamanında toplanması sağlanacaktır. Bu, gerçek zamanlı veri akışları ve düzenli veri yenileme döngülerini de içermektedir. 3.3 Veri Entegrasyonu ve Kalite Güvencesi Veri entegrasyon teknolojilerinin uygulanması ve düzenli veri kalite değerlendirmeleri ile, tutarsızlıkların ve anormalliklerin belirlenmesi ve düzeltmesi kolaylaşacaktır. 4. Veri Analitiği ve İçgörüler 4.1 Gelişmiş Analiz Altyapısı Veri Madenciliği, makine öğrenmesi ve yapay zekâ gibi gelişmiş analiz tekniklerini kullanarak veriden değerli bilgiler çıkarmak amaçlanmaktadır. Merkez bankacılığı özgül veri işleme ve modelleme ihtiyaçları bağlamında buna öngörü modellemesi, duygu analizi ve anormallik tespiti gibi analiz yöntemleri dahil edilebilir. 4.2 Öngörü Modellemesi Ekonomik trendlerin tahmini, risk değerlendirme ve para politikası kararlarının veri ve bilgi ile desteklenmesi için öngörü modelleri geliştirilmesi amaçlanmaktadır. Bu modeller, yeni veri ve içgörülere göre sürekli olarak iyileştirilecektir. 4.3 Veri Görselleştirme Karmaşık veriyi anlaşılır ve işlenebilir bir biçimde sunmak için veri görselleştirme araçlarının uygulanması amaçlanmaktadır. Tasarlanacak etkileşimli panolar aracılığıyla, paydaşların veriyi bağımsız olarak derinlemesine keşfetmeleri, incelemeleri, düzenlemeleri ve analizlerde kullanmaları sağlanacaktır. 5. Veri Güvenliği ve Gizlilik 5.1 Siber Güvenlik Önlemleri Veriyi ihlallerden ve yetkisiz erişimden korumak için sağlam siber güvenlik önlemleri uygulamak amaçlanmaktadır. Sistemsel ve yapısal zayıflıkları belirlemek için düzenli güvenlik denetimleri ve penetrasyon testleri gerçekleştirilecektir. 5.2 Veri Gizliliği Uyumu Kişisel ve hassas bilgilerin korunması için veri gizliliği düzenlemeleri ve standartlarına uyum sağlanması amaçlanmaktadır. 5.3 Erişim Kontrolü Rollere ve sorumluluklara dayalı olarak veri erişimini sınırlamak için sıkı erişim kontrolleri uygulanacaktır. Yetkisiz veri kullanımını önlemek için erişim kayıtları düzenli olarak izlenecek, raporlanacak ve paydaşlara geri bildirimde bulunulacaktır. 6. Veri Altyapısı 6.1 Donanım ve Yazılım Verimli bir şekilde veri işleme, depolama ve analizlerini desteklemek için modern donanım ve yazılım çözümlerine yatırım yapılması öngörülmektedir. 6.2 Uzaktan Erişim Kümeleme ve GPU bilişim sistemleri araştırılarak uzaktan erişimde gerekli olan, işlem gücü, depolama, saklama ve güvenlik hizmetlerinin ölçeklendirilmesi, yönetimi ve en verimli bir şekilde sunulması amaçlanmaktadır. 6.3 Veri Depolama Veri saklama politikalarına uygun olacak şekilde, yapılandırılmış ve yapılandırılmamış verileri barındıran güvenli ve yedekli bir veri depolama çözümü hayata geçirilecektir. 7. Kapasite Geliştirme 7.1 Eğitim ve Yetenek Geliştirme Çalışanları veri analitiği ve analizi, veri madenciliği ve makine öğrenmesi ile veri yönetimi konularında eğitmek ve bu konulardaki en iyi uygulamalar temel olmak üzere geliştirmek için düzenli eğitim programları sunulması amaçlanmaktadır. 7.2 İşe Alma Stratejileri Veri uzmanları ve analistler işe alınarak Merkez Bankasının veri yeteneklerinin artırılması amaçlanmaktadır. 7.3 Eğitim Kurumlarıyla İşbirliği Üniversiteler ve araştırma kurumlarıyla işbirliği yaparak veri bilimi ve analitiği alanındaki bilgi, deneyim ve yeteneklerin ve akademik uzmanlığın kullanılması amaçlanmaktadır. 8. Veri Stratejileri Uygulama Yol Haritası 8.1 Kısa Vadeli Hedefler Veri Yönetişim Kurulu'nu kurmak ve veri Yönetişim politikalarının taslağını oluşturmak. Temel veri analitiğini başlatmak için veriyi tanımlamak ve kataloglamak. Temel veri analitiğini başlatmak. 8.2 Orta Vadeli Hedefler Ekonomik tahminler için gelişmiş analitik modeller geliştirmek ve uygulamak. Veri güvenliği önlemlerini güçlendirmek ve siber güvenlik denetimine tabi tutmak. İç paydaşlar için gelişmiş veri görselleştirme araçlarını uygulamak. 8.3 Uzun Vadeli Hedefler Veri yönetimi için olgun ve kapsamlı bir çerçeve oluşturmak. Merkez Bankası içinde veri analitiği için bir mükemmeliyet merkezi kurmak. Teknolojik gelişmelerle uyumlu kalmak için veri stratejilerini sürekli olarak yenilikçi hale getirmek. 9. İzleme ve Değerlendirme 9.1 Anahtar Performans Göstergeleri (APG) Veri stratejilerinin etkililiğini ve verimliliğini ölçmek için veri doğruluğu, işleme hızı ve veri odaklı kararların Merkez Bankasının hedefleri üzerindeki etkisi gibi anahtar performans göstergeleri belirlenecektir. 9.2 Denetim ve İnceleme Veri yönetimi politikalarına, güvenlik önlemlerine ve stratejik hedeflere uyumu denetlemek için düzenli denetim ve incelemeler yapılacaktır. 10. Sonuç Veri Yönetim Stratejileri Raporu, Türkiye Cumhuriyet Merkez Bankası'nın temel görevlerini etkili bir şekilde yerine getirebilmesi için verinin yönetimi, analizi ve kullanımını sağlamak üzere bir çerçeve oluşturmayı amaçlamaktadır. Bu stratejilerin benimsenmesiyle Merkez Bankası, ekonomik ve finansal istikrarı artırmayı, bilinçli karar alma süreçlerini desteklemeyi ve veriye dayalı bilgilerle inovasyonu teşvik etmeyi hedeflemektedir. Daha ayrıntılı uygulama planları ve zamanlamalar için lütfen eklenen uygulama yol haritasına başvurunuz. 11. Uygulama Yol Haritası 1. Yıl: (Kısa Vade) Veri Yönetişim Kurulu'nu kurulması ve veri sorumlularının atanması, Temel veri yönetimi politikalarının geliştirilmesi ve uygulanması, Temel veri kaynaklarını belirlenmesi ve kataloglanması, Veri kalitesi değerlendirmeleri, Ekonomik tahminler için gelişmiş analitik modellerin geliştirilmesi ve uygulanması, Veri güvenliği önlemlerinin güçlendirilmesi ve siber güvenlik denetimleri, İç paydaşlar için veri görselleştirme araçlarının uygulanması, Veri analitiği becerilerinin geliştirmek için kapasite geliştirme programlarının başlatılması, Deneyimlerden yola çıkarak veri yönetimi politikalarının geliştirilmesi ve genişletilmesi, İç ve dış paydaşlar için gelişmiş veri görselleştirme araçlarının uygulanması, Kapasite geliştirme çabalarının sürdürülmesi ve yetenek gelişim süreçlerinin değerlendirilmesi ve Veri bilimi ve analitiği konularında üniversitelerle işbirliği fırsatlarının araştırılması. 2. Yıl: (Orta Vade) Merkez bankası içinde veri analitiği için bir mükemmeliyet merkezinin oluşturulması, Finansal düzenlemelerde risk değerlendirmesi için öngörü modellemelerinin uygulanması, Endüstri en iyi uygulamalara dayalı olarak siber güvenlik önlemlerinin düzenli olarak güncellenmesi ve Veri Stratejilerinin etkililiğinin değerlendirilmesi ve gerektiğinde ayarlamalar yapılması. 3. Yıl ve Sonrası: (Uzun Vade) Teknolojik gelişmelere uyum sağlamak için veri stratejilerinin sürekli olarak yenilikçi hale getirilmesi, Merkez Bankası içinde veriye dayalı karar alma kültürünün teşvik edilmesi, Temel görevlerin ötesinde daha geniş politika insiyatiflerinde veriyi kullanma fırsatlarının araştırılması ve Veri girişimleri konusunda diğer merkez bankaları ve finansal kuruluşlarla işbirliği fırsatlarının değerlendirilmesi 12. Sözlük Veri Yönetişim: Veri varlıklarını yönetme, veri kalitesini güvence altına alma, güvenliği sağlama ve uyum sağlama süreçleri. Veri Sorumluluğu: Bir organizasyon içinde veriyi doğruluk, bütünlük ve uygun kullanım açısından yönetme uygulaması. Öngörü Modellemesi: Gelecekteki sonuçları veya davranışları tahmin etmek için geçmiş verileri kullanma süreci. Veri Görselleştirme: Karmaşık veriyi anlamak ve içgörüler elde etmek için grafiksel veya görsel formatlarda sunma işlemi. Siber Güvenlik: Bilgisayar sistemlerini, ağları ve verileri hırsızlığa, zarara veya yetkisiz erişime karşı koruma uygulaması. Veri Gizliliği: Kişisel ve hassas bilgileri yetkisiz erişime ve kullanıma karşı koruma işlemi. Erişim Kontrolü: Bir organizasyon içinde belirli kaynaklara veya bilgilere kimlerin erişebileceğini düzenleme süreci. Anahtar Performans Göstergeleri (APG): Bir organizasyonun hedeflerine ulaşma derecesini değerlendirmek için kullanılan nicel ölçümler. 13. İletişim Bilgileri Veri Yönetimi Stratejileri Raporu ile ilgili sorularınız için lütfen iletişime geçiniz Murat Çakır Uzman Yapısal Ekonomik Araştırmalar Genel Müdürlüğü murat.cakir@tcmb.gov.tr 02167738035 14. Ekler Murat Çakır 2017, ‘A conceptual design of "What and How Should a Proper Macro-Prudential Policy Framework Be?" A Globalistic Approach to Systemic Risk and Procuring The Data Needed,’ IFC Bulletins chapters, in: Bank for International Settlements (ed.), Uses of Central Balance Sheet Data Offices' Information, Volume 45, 2017, Bank for International Settlements (https://www.bis.org/ifc/publ/ifcb45d.pdf) Murat Çakır 2016 ‘National Data Centre and Financial Statistics Office: A Conceptual Design for Public Data Management’, Paper 2016 (https://mpra.ub.uni-muenchen.de/74410/9/MPRA_paper_74410.pdf) Murat Çakır 2014, ‘From Data to Information and from Information to Policy Making - The Story of the "Integrated Company and Industry Analysis Platform",’ IFC Bulletins Chapters, in: Bank for International Settlements (ed.), Proceedings of the Porto Workshop on "Integrated Management of Micro-Databases", volume 37, 2014, pages 171-178, Bank for International Settlements (http://www.bis.org/ifc/publ/ifcb37zm.pdf) ‘CBRT Statistics, Data and Database Management Manual’ Başkan yrdlarına mail metni Sayın Başkanım, Türkiye Cumhuriyet Merkez Bankası, kanunuyla kendisine verilen görevleri etkili bir şekilde yerine getirebilmek için, veriyi stratejik bir varlık olarak kullanma ve bilgiye dayalı ve veri odaklı karar almanın öneminin bilinciyle çok uzun yıllardır ilgili alanlarda gereken çalışmaları yerine getirmiş ve gerekli yatırımları yapmıştır. Bu yönüyle, ülkemizdeki en erken dijitalleşme çalışmalarının yürütülmesi, ulusal ve uluslararası eşgüdüm ve işbirliği çerçevesinde çeşitli çalışmalarında yer alınan kurullar ve ortak yürütülen projelerdeki faaliyetler, veri üretimi ve paylaşımı, ve benzeri bir çok konuda öncü olmuştur. Kurum içinde gerçekleştirilen çalışma ve projelerin önemli bir bölümü de ya dünya çapında ilk ya da benzer örneklerinin ötesinde olma özelliği taşımaktadır. Bir süredir, TCMB'nin veri ve bilişim sistemleri ile ilgili yönetsel bazı zafiyetlerin geliştiği, bu alanlardaki sorunların hem iç kullanıcılar hem de kamuoyu açısından riskler oluşturduğu gözlemlenmektedir. Kurum içinde veri üreten ve kullanan birimlerin BTGM ile eşgüdüm içerisinde bahsi geçen alanlar ve barındırdıkları sorunlara ilişkin çalışmaları ve çözüm üretmeleri öncelikli bir konu durumuna gelmiştir. Bu önceliğin ivedilikle yerine getirilmesi ile kurumun işleyişinin sürdürülebilir kılınması yanında TCMB'nin kamuoyunu aydınlatma görev ve sorumluluğunun sağlanması da mümkün olacaktır. TCMB’nin, veri ve kullanımının önemine dair sorumluluk bilinci çerçevesinde, yeni bir bakış açısı ve enerjiyle her konuda olduğu gibi veri süreçlerinde de çağın gereklerini yakalaması ve öncü rolü üstlenmesi gerekliliği açıktır. Bu bağlamda, hazırladığım ve ekte sunulan Veri Yönetimi Stratejileri Raporu ile verinin etkili bir şekilde yönetilmesi, güvenliğinin sağlanması ve tam potansiyeliyle kullanılmasını sağlayan bir çerçeve oluşturulması amaçlanmıştır. Halihazırdaki durumun değerlendirildiği bir rapor talep etmeniz halinde birimlerle iletişime geçilmek suretiyle hazırlanacak ve ayrıca sunulacaktır. Bilgilerinize arz ederim İyi çalışmalar